
Новости проекта, приёмная часть почти завершена. Немного оптимизации работы и доработка кода, чтобы приступить к передающей части.
Главным прогрессом стал перенос кода, занимающегося обработкой, фильтрацией и выводом звукового потока в STM32 модуль.
Смотря на опыт своих коллег из UHSDR был реализован фильтр Гильберта, ФНЧ и прочие модули на DSP подсистеме процессора. Это позволило разгрузить FPGA и в будущем позволит оперативно менять параметры фильтров под нужды пользователя (например частоту среза).
Также, весь модуль WM8731 теперь тактируется и полностью подключен к STM32. На нём же реализованы АРУ, Loopback система для проверки микрофона, доработан FFT, водопад и прочее. Всё общение с кодеком происходит по средством DMA.
Также, теперь настройки и параметры хранятся во Flash-памяти.
Файлы проекта будут хранится в GitHub репозитории https://github.com/XGudron/UA3REO-DDC-Transceiver (подключение выводов и схемотехника может отличаться на момент просмотра от времени написания статьи, если нужны старые версии — смотрите историю старые ревизии кода в репозитории).
Начал рисовать схему соединения и модулей в DipTrace (есть в файлах проекта).
Посчитана примерная смета проекта, сейчас это 7241руб, её можно существенно снизить, если разработать свою плату, а не собирать трансивер из готовых китайских модулей.
У меня нет особых навыков в измерении характеристик приёмников, да и аппаратуры соответствующей почти нет, но подключив вывод к звуковой плате компьютера было измерено, что шумовая планка составляет -100дБ (предел микрофонного входа звуковухи), а подавление зеркального канала более -90дБ (сигнал с генератора показывает -10дБ в нужной полосе, и уходит в шумы -100дБ при смене LSB/USB). Если раздобуду калиброванный генератор сигнала, то измерю текущую чувствительность.
Так как в ходе подготовки статьи не было интересных аппаратных изменений, расскажу про организацию передачи звуковых данных из FPGA в кодек.
Проблема заключается в том, что если прочитать данные, обработать их фильтрами Гильберта и FIR, и отправить на кодек — то получится сильная рваная зарежка. Для этого, пока аудио-кодек занимается передачей звука, надо успевать подготовить новую порцию данных.
После долгих (очень долгих) экспериментов я остановился на следующей схеме работы:
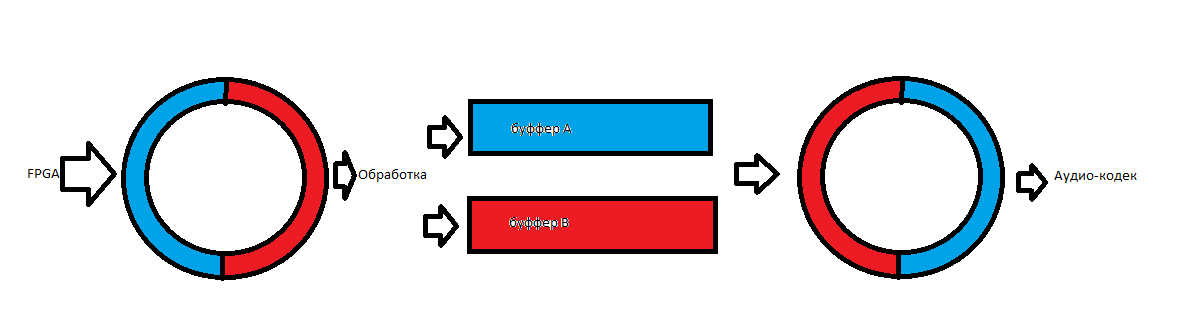
- Из FPGA, на частоте приближенной к частоте дискретизации аудио-кодека (а 100% соответствия добиться не получается, т.к. PLL I2S шины работает чуть ниже 48кгц и периодически «гуляет») заполняет кольцевой буффер, как только он доходит до его конца, данные начинают заполнятся с начала.
- Обработчик звука (там где происходит вся фильтрация) берёт ровно половину буффера FPGA до текущей позиции, производит свои преобразования и складирует результат в один из буфферов, сначала А, потом B, по очереди.
- В это время DMA аудио-кодека тоже работает в кольцевом режиме и вызывает 2 прерывания: по завершению кольца и на его середине.
- Когда мы находимся на конце буффера, мы загружаем вторую половину кольца новыми данными из буффера аудио-процессора, а когда находимся на середине — первую половину буффера. Тем самым, DMA, всегда имеет «хвост» из свежих данных, готовых к передаче. В связи с этим звук получается достаточно чистым и без искажений.
Полезные ссылки:
Здравствуйте. Когда будете оформлять проект с генератором на 96МГц, можете заострить внимание, какие параметры нужно менять в случае смены тактовой частоты? У меня есть генератор на 122,88МГц от соответствующего проекта.
Да, конечно!
Предварительно список следующий:
1. (FPGA) Перенастроить NCO на нужную частоту
2. (FPGA) Перенастроить CIC и CICCOMP на новый уровень децимации
3. (FPGA) Перенастроить PLL для выдачи нужных частот на фильтр CICCOMP
4. (STM32) Изменить формулу расчёта частоты